半导体行业观察 来源
clamchowder 作者
不提供二次转载
为数众多的半导体初创公司希望打入市场,它们要么拥有一些大型 AI 训练芯片,要么拥有一些超快速的小型推理设备,或者可能是针对一个特定问题的 HPC 专注设计。一些公司资金充裕,其中不乏融资超过1亿美元的公司,还有一些资金支持超过10亿美元。在本文中,我们着眼于 Tachyum,这是一家美国/欧盟芯片初创公司,它于2018 年首次出现在我们的视野中,其高性能、高频率的处理器设计令人惊叹,涵盖了诸多细分市场。在 2022 年的今天,他们已经修改了早期的设计,总而言之,它看起来更像是一个可以真正打破常规的计算架构。
我们所要讨论的是拥有 128 核、每核 2×1024 位向量、5。7 GHz、1 TB/秒的 DRAM的庞然大物。有人说我们的数据中心的热余量用完了,这显然是错误的,Tachyum 证明了这一点。在本文中,我们将介绍新设计与旧设计的比较,以及我们可以从 Tachyum 的披露中收集到哪些信息。
01
Tachyum Prodigy 2022
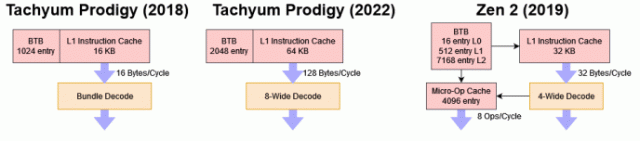
今天,Tachyum 仍然称他们的架构为“Prodigy”。但他们已经根据客户的反馈对其进行了彻底改革。VLIW 捆绑包被更传统的 ISA 取代, 硬件调度功能更强大,提高了每个时钟的性能。缓存层次结构也发生了重大变化。2022 Prodigy 的变化足够广泛,以至于对 2018 年 Prodigy 所做的大部分分析都不再适用。
在高层次上,2022 Prodigy 仍然是一个非常广泛的架构,具有巨大的向量单元:
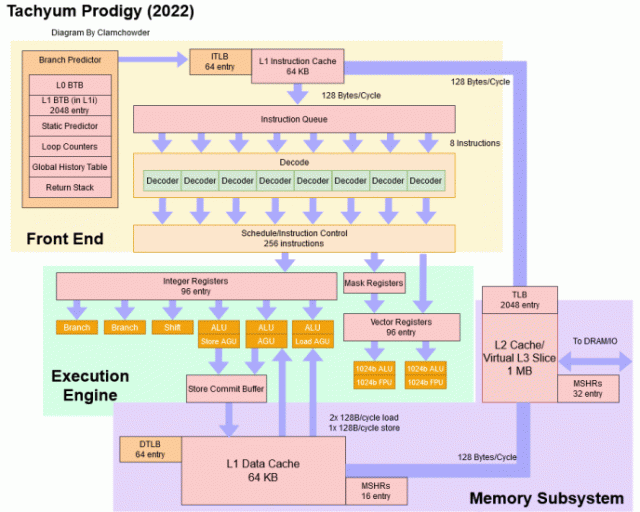
与 2018 Prodigy 一样,2022 Prodigy 的目标是极高的时钟速度和高内核数。事实上,这些目标已经被提高了,时钟速度从 4 GHz 提高到 5。7 GHz,内核数从 64 增加到 128。本文中我们将更深入地了解细节。
02
再见捆绑包,你好 Sane ISA
Tachyum 最初试图通过将指令集与底层硬件实现紧密联系来简化 CPU 设计。VLIW 包允许非常简单的解码和映射逻辑。编译器协助调度,它会设置“停止位”来标记可以并行发布的指令组。这种方案表面上类似于 Nvidia 在 Kepler 和后来的 GPU 架构中使用静态调度,并让内核跳过硬件中的依赖检查。
但是将 ISA 绑定到硬件会产生前向兼容性问题。例如,如果新架构具有不同的指令延迟,则必须设置不同的停止位。Tachyum 的潜在客户不会接受产品世代之间的 ISA 更改。在实践中,像将 ARM 支持添加到复杂的软件项目这样“简单”的事情可能需要 18 个月以上的时间。支持新的 ISA 必须是一次性投资,而不是每次 CPU 升级都会重复的投资。
最新的 Prodigy 架构通过放弃原来的 VLIW 方案转而采用更传统的 ISA 来解决这个问题。指令有四个或八个字节长。编码不再包含“停止位”,这意味着现在Prodigy 在硬件中进行依赖性检查,而不是依赖硬件来标记独立指令组。
03
前端和分支预测
尽管放弃了 VLIW 设置,Prodigy 仍然可以维持每个周期 8 条指令——对于目标为 5。7 GHz 的 CPU 来说,这是一项了不起的成就。根据 Rado所说,这个内核宽度对于在 AI 和 HPC 负载中实现最大性能是必要的。在整数工作负载中,4 宽的内核就足够了,而增加到 8 宽的内核只会将性能提高 7-8%。但是,AI 或 HPC 程序中的一次循环迭代可能会执行两条向量指令、两次加载、递增循环计数器并有条件地分支。将内核宽度提高到 8 宽将使 Prodigy 在每个周期完成一个循环迭代。
为了保持这种吞吐量,Prodigy 可以从 L1 指令高速缓存中提取每个周期128 字节。考虑到 64 个字节足以包含 8 条指令,这绝对是大材小用。Tachyum 可能选择了更多的获取带宽,以在所占用的分支周围保持高吞吐量。Prodigy 没有大的 L0 BTB,因此与 Zen 3 和 Golden Cove 相比,它可能会在所采用的分支周围遇到更多的指令获取停顿问题。通过一次获取 128B 字节,前端可以在 BTB 延迟丢失一个周期后“赶上”。
Prodigy 的分支预测器也得到了改进。BTB容量翻倍至2048条,预测算法是2018 Prodigy中gshare one的改进版。但总的来说,Prodigy 的预测器与最新的 AMD、ARM 和 Intel 高性能内核中的预测器不同。AMD 的 Zen 3 有一个 6656 入口的主 BTB。ARM 的 Neoverse V1 拥有 8192 个 BTB 入口,而英特尔的 Golden Cove 拥有令人难以置信的 12K 入口 BTB。BTB 容量并不是唯一的缺点。Prodigy 继续使用绑定到指令缓存的 BTB。这简化了设计,因为无需进行单独的 BTB 查找——L1i 查找为您提供指令字节和分支目标。AMD 的 Athlon 也做了类似的事情,ARM 在 2010 年代中期使用了这个方案。但是来自 AMD、ARM 和 Intel 的现代内核已经转移到解耦 BTB,允许它们在代码占用量超过 L1i 容量时保持高指令带宽。对于耦合的 BTB,L1i 未命中意味着 BTB 未命中。并且不知道下一个分支将去哪里,这大大降低了在指令缓存未命中后您可以有效预取的距离。但是 Tachyum 正在使用标准单元库,并以非常高的时钟速度为目标,而使用这些标准单元库的解耦 BTB 被认为过于昂贵。
为了解决这个问题,Tachyum 将 L1i 容量增加到 64 KB,是 2018 年 Prodigy 的四倍,以确保 L1i 失误减少。Rado 指出,specint2017 中的 64 KB L1i 未命中率低于 0。5%。我们对 Ampere Altra 的 64 KB L1i 的观察大致一致。更大的 L1i 还有助于提高电源效率,并最大限度地减少与 L2 带宽上的数据端的争用。
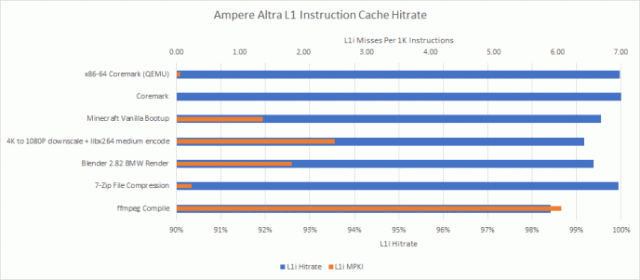
ARM 采用了更大的 64 KB L1i 高速缓存,效果极佳,并且 L1i 未命中率低。
2022 Prodigy 还继续依赖于相当过时和基本的 gshare 预测算法,而现代 CPU则使用更复杂的技术,可以在给定的存储预算下实现更好的预测精度。Tachyum 考虑构建更高级的分支预测器,但同样,标准单元库意味着实现 TAGE 预测器会过多地降低时钟速度。由于高时钟速度要求,除了感知器预测器 - 您可以想象在一个时钟周期内汇总一批权重需要做很多事情。包含本地历史的方案也不可行,因为高获取带宽意味着每个周期必须执行多个预测。具有本地历史的多个预测将需要每个周期进行多次历史表查找。因此,Tachyum 坚持使用基于全局历史的预测器,并且每块 8 条指令进行预测。这使分支预测器保持简单,同时让它跟上 Prodigy 内核宽度所需的预测带宽。

英特尔的 Rocket Lake 内核,带有分支预测器存储和其他前端缓存标记。图片来自 Fritzchens Fritz,Clam 注释
Rado 提到 Prodigy 的未来版本可以使用自定义单元,这将让他们考虑更高级的分支预测器,同时仍然以非常高的时钟速度为目标。相比之下,英特尔似乎在分支预测器中使用了在内核其他地方看不到的自定义 SRAM 单元。AMD 采用了不同的方法,将相同的 SRAM 单元用于分支预测器存储、L1 指令缓存和微操作缓存。

AMD 的 Zen 3 内核,带有分支预测器存储和其他标记的前端缓存。图片来自 Fritzchens Fritz,Clam 注释
Zen 3 展示了可以使用标准单元构建最先进的分支预测器,尽管可能不是 Prodigy 的目标 5。7 GHz 速度。
04
后端:巨大的向量单元和完整的 OoO?
如果你不能有效使用它,那么建立一个巨大的内核并没有多大意义。为此,Tachyum 放弃了他们 2018 年的设计,并在硬件中实现了深度重新排序功能。2022 Prodigy 可以跟踪多达 256 条正在运行的指令,其中整数寄存器有 96 个重命名,向量寄存器也有同样多的重命名。它可以重新排序过去的各种依赖项。根据 Tachyum 的描述,Prodigy 可以像 AMD、ARM 和 Intel 的内核一样完全乱序执行。但不是使用更传统的无序引擎,而是使用检查点方案。对于可能导致异常的指令,例如未命中缓存的加载,Prodigy 会保存带有寄存器状态的检查点。如果该指令确实导致异常,则该检查点用于提供精确的异常处理。2022 Prodigy 可以保存多个检查点,而2018 Prodigy只能保存一个检查点。这是一个重大改进,就执行单元而言,Tachyum 为 2022 Prodigy 配备了两个巨大的 1024 位向量单元,并增加了向量寄存器宽度以匹配。因此,2022 Prodigy 的矢量宽度是 2018 Prodigy 的两倍,并且矢量吞吐量比当今任何通用 CPU 都要高。甚至英特尔的 Golden Cove 也只有两个 512 位向量单元。
05
缓存子系统
在重新设计 Prodigy 架构以在硬件中进行更多重新排序,从而使其能够为 AI/HPC 应用程序保证更多带宽后,Tachyum 面临着保持这些内核输入的挑战,同时,提供以高速时钟运行的 1024 位向量单元也是一项艰巨的挑战。首先,L1D 数据路径的宽度增加了一倍,以匹配向量长度的增加。在 5。7 GHz 时,Tachyum 内核可以从其 L1D 以接近 1。5 TB/s 的速度加载数据。L2 可以在每个周期向 L1D 提供完整的 128B 高速缓存行,带宽约为 730 GB/s。相比之下,英特尔的 L1D 和 L2 缓存的每周期负载带宽是 Prodigy 的一半,AMD 则更落后。Zen 2 和 Zen 3 在 L1 和 L2 的每周期带宽是英特尔的一半。当然,Prodigy 的时钟频率高于 Intel 或 AMD 当前的 CPU,因此具有巨大的缓存带宽优势。
Zen 2 似乎能够通过在未记录的性能计数器上使用计数屏蔽来跟踪至少 32 个未决的 L2 未命中。
为了维持高带宽和隐藏延迟,2022 Prodigy 改进了内存级并行性 (MLP)。具体来说:
这是对 2018 版本的重大改进,在 2018 版本中,可实现的 L3 带宽和内存将受到其低 MLP 的限制。它与 Zen 3 和 Golden Cove 位于同一个块,但从绝对意义上来说可能会稍逊一筹。
2022 Prodigy 还增加了缓存容量,以更好地处理具有大内存占用的负载。L1 数据缓存的容量翻了两番,从 16 KB 增加到 64 KB。与 2018 Prodigy 相比,每核 L2 和 L3 缓存容量没有增加,但 2022 Prodigy 放弃了单独的 L2 和 L3 布局,转而采用虚拟 L3 设置。空闲内核将允许活动内核将其 L2 用作虚拟 L3,从而提高低线程负载的缓存命中率。当一个内核从它的 L2 驱逐一条线时,它会检查周围的内核,看看它们的 L2 是否可以接受被驱逐的线,只有属于非活动内核的 L2 缓存才会接受这些请求。
对我们来说,这个设置一点也不简单,并且围绕这个虚拟 L3 的实现方式会有很多调整。听起来一个物理内存可以缓存在多个虚拟 L3 切片中,具体取决于哪些对应的内核处于空闲状态,更多的切片检查意味着更多的互连流量。Tachyum 还希望将数据尽可能靠近所占用的内核,而可能的位置越少意味着这方面的灵活性越低。与 Intel、AMD 和 ARM 使用的更简单的方案相比,正确设置这个虚拟 L3 听起来像是多维优化问题。
转换性能也很重要,因此 Tachyum 将最后一级 TLB 大小从 256 增加到 2048 个条目。在条目数方面,它与 Zen 2、Zen 3 和 Golden Cove 相匹配。为了进一步提高 TLB 覆盖率,Prodigy 确实以 64 KB 的页面大小和 32 MB 的大页面来处理更大粒度的任务。2048 个条目的 L2 TLB 将覆盖 128 MB 和 64 KB 页面。ARM 和 x86 主要使用 4 KB 页面以及 2 MB 大页面用于客户端应用程序。较大的页面大小往往会浪费更多的内存,但这对于通常具有数百 GB DRAM 的服务器来说并不是什么大问题。
06
内存带宽
对于不适合缓存的工作负载,DRAM 带宽可能是个问题。正如我们之前提到的,Prodigy 的计算与内存带宽比高于当前的 CPU 和 GPU。起初,Tachyum 试图通过实现封装 HBM 来解决这个问题。但 HBM 的容量非常低,这意味着如果 Tachyum 想要占领服务器市场,它并不是一个可行的选择。HBM 解决方案对于 HPC 和 AI 应用程序来说是可以接受的,但 Rado 指出,Nvidia 已经拥有该市场的大部分份额,而与服务器市场相比,剩下的市场很小。保留两种内存选项是不可行的,因为芯片上没有足够的边缘空间来容纳 DDR 和 HBM 控制器。
因此,Tachyum 选择了一个非常强大的 DDR5-7200 设置,带有 16 个控制器,总内存总线宽度为 1024 位。这使它的带宽与 Nvidia 的 RTX 3090 GPU 差不多。DDR5-7200 今天还不存在,但 Tachyum 预计只有 AI 和 HPC 客户才需要性能最高的内存设置。这些客户通常会购买整个系统而不是组件,从而允许集成商对可达到 7200 MT/s 的内存模块进行封装。服务器应用程序通常不受带宽限制,并且可以使用速度较慢的 DDR5。
但即使使用 DDR5-7200,Prodigy 的海量矢量单元和高时钟意味着它比其他 CPU 和 GPU 具有更低的带宽与计算比。Tachyum 希望通过使用内存压缩来缩小这一差距,这有点像 GPU 如何进行增量颜色压缩以降低带宽需求。但与 GPU 不同的是,Tachyum 正在为 AI 和 HPC 应用程序调整内存压缩算法。最后,Tachyum 以更大的粒度进行 ECC,允许内存控制器使用一些 ECC 线路来代替传输数据。
07
提高仿真性能
Tachyum 的 Prodigy 引入了新的 ISA,因此不会像 x86 和 ARM 那样享有强大的软件生态系统。这是一个严重的问题,因为如果世界上最好的芯片不能运行用户需要的软件,它就完全一文不值。为了解决这个问题,Tachyum 正在寻找 QEMU,它可以模拟另一种架构并允许 x86 和 ARM 二进制文件在 Prodigy 上执行。但仅 QEMU 是不够的,因为仿真性能通常很差。例如,我们在 Ampere Altra 上运行 QEMU 下为 x86-64 编译的 CoreMark。
为了提高 x86 二进制文件的仿真性能,Prodigy 可以切换到“严格”内存排序模式。Tachyum 也在 QEMU 中完成了软件工作以提高性能。就绝对值而言,30-40% 的性能损失仍然很严重。但是运行所需的软件比绝对性能更重要,如果芯片不能运行所需的软件,那么世界上所有的性能都是无关紧要的,因此 Tachyum 已经在 QEMU 中投入了大量精力,以确保硬件至少在发布时可用。
08
评估架构
Tachyum 对 Prodigy 进行了大量修改,因此2018 和 2022 版本基本上是不同的架构。总结主要的管道变化如下:
2022 Prodigy 的变化使其成为比 2018 Hot Chips 上展示的版本更具竞争力的架构。Prodigy 不再严重依赖编译器,采用传统的 ISA,并具有不错的硬件重新排序功能,这些是我们对 2018 版本最大的担忧,我们很高兴看到它们得到解决。2018 版本中的其他弱点,如微小的 L1 缓存,也得到了纠正。这给我们留下了一个带有巨大矢量单元的宽内核,以针对高内核数芯片的前所未闻的时钟。
对于 HPC 和 AI,我预计 Prodigy 将极具竞争力。它具有足够的重新排序深度和内存级别的并行能力,可以充分利用内存带宽。虽然它的内存带宽与计算比率低于竞争解决方案,但 Prodigy 确实有很多技巧可以缓解这种情况。即使没有这些技巧,Prodigy 仍然拥有比 AMD 的Milan 或者 Genoa更强大的 DRAM 子系统。富士通的 A64FX 确实具有相当的 DRAM 带宽,但它使用 HBM,这极大地限制了它的内存容量。
服务器市场是一个更难的问题。Prodigy 拥有不错的大型 L1 缓存、不错的重新排序能力、非常高的时钟速度和高核心数。但是它的分支预测器远远不是最先进的,每个核心的最后一级缓存容量很低(尤其是与 AMD 相比)。更糟糕的是,过渡到新的 ISA 对任何大公司来说都是一件头疼的事情。不过,我认为 Prodigy 有一个不错的机会,因为它的时钟速度优势是如此之大,不仅可以掩盖它的缺点,更可以让它在核心数量和单核性能方面都比其他所有人的服务器产品都具有优势。Tachyum 可以说服人们使用他们的新 ISA 和羽翼未丰的软件生态系统,以便利用 Prodigy 的高性能。
如果 Prodigy 快要实现其雄心勃勃的(高速)时钟目标,它确实很有可能成为“通用处理器”,至少在纸面上是这样。它将类似于 GPU 的矢量吞吐量与 CPU 的单线程性能相结合。代价是极高的功耗。128 核 Prodigy 在加载矢量单元的情况下可以达到近 950W 的功率。即使是 32 核、3。2 GHz 低功耗 SKU 也被指定为 180W——并不比基于 Zen 2 的 Epyc 7502P 好,后者尽管使用了小芯片设置和较差的工艺节点,但它以类似的 180W TDP 提升到 3。35 GHz。在服务器中,整型计算不太可能使 Prodigy 消耗 TDP 数据所显示的那么多功率。但是高 TDP 等级仍然是一个问题,因为冷却系统必须针对最坏的情况进行设计。
09
关于 5。7 GHz
就个人而言,我怀疑 Prodigy 能否实现其 5。7 GHz 时钟目标。Tachyum 正在采用一些策略来帮助在高时钟下控制功率和面积。我们目前无法确切透露那是什么,但我认为这还不够。将两个 1024 位向量单元推送到这些时钟将是一项令人难以置信的壮举。流水线长度看起来太短了。在2018年, Prodigy 有一个从取指令到执行指令的 9 阶段整型流水线。在2022年 Prodigy 增加了一个用于硬件依赖检查的阶段,使整型流水线达到 10 个阶段。对于以 5。7 GHz 为目标的设计来说,这非常短。作为比较,Agner Fog 指出,在英特尔的 Golden Cove 上,错误预测惩罚(对应于流水线长度)超过 20 个周期。AMD 的优化手册称 Zen 3 的误判惩罚范围为 11-18 个周期,常见情况为 13 个周期。流水线长度与 Prodigy 相似的 CPU 无法达到 5 GHz。Neoverse N1 有 11 级流水线,运行频率不高于 3。3 GHz。AMD 的 Phenom 有 12 个周期的错误预测惩罚,运行频率为 3。7 GHz。
如果我们就 Tachyum 的芯片图而言,假设它占据 500 mm2,单个 Prodigy 内核的空间远低于 3 mm2,从而引发热点问题。
发热问题也须考虑。AMD 的 Zen 3 的时钟频率可以超过 5 GHz,但在低线程负载下面临冷却挑战,因为它们的低核心面积意味着非常高的热密度。Tachyum 预计 Prodigy 将占据不到 500 平方毫米的空间。Tachyum 发布的模具平面图效果图表明,每个核心的尺寸小于 3 mm2。Zen 3 核心的面积约为 3。78 平方毫米,包括 L2。Prodigy 核心在某些领域可能不那么复杂,例如分支预测器,但在其他领域(例如向量单元)也更复杂。我认为当核心被推到 5。7 GHz 时很可能会出现热点问题。
最后一点,考虑策略实用性的一种方法是查看其他公司采用相同策略的频率。如果对于一家小型初创公司来说,采用 5 GHz 以上的 1024 位矢量单元的 8 位宽内核是可以实现的,那么 AMD、ARM 和英特尔在过去十年中肯定一直在偷懒。哦,把 Nvidia 也算上——他们的 Kepler、Maxwell 和 Pascal 架构有 32 位宽的 FP32 ALU,基本上是 1024 位。或者,要让一个广泛的架构达到如此高的时钟频率真的很难,而且小型初创公司不太可能做到这一点。我并不是说 Prodigy 不可能达到 5。7 GHz,因为 AMD 的 Zen 4 显然达到了 5。85 GHz。也许台积电的 5nm 工艺就是这么神奇。但是通过巨大的矢量单元、高核心数和相对较短的流水线来实现这种时钟速度看起来像是一座太远的桥梁。因此,让我们看看如果 Prodigy 未能达到其时钟目标,它的竞争力将如何。
10
HPC and AI
即使没有高时钟,Prodigy 也有大量的吞吐量,这要归功于巨大的矢量单元。即使在 3 GHz 下,它的浮点数处理能力也稳居 GPU 领域。与之竞争的 CPU 甚至不在同一个层次。
*假设 Golden Cove 在 Sapphire Rapids 中有 2×512 位向量单元
有趣的是,以较低的时钟运行还为 Prodigy 提供了更平衡的计算吞吐量与内存带宽的比率。在 5。7 GHz 时,Prodigy 需要一些技巧来减少内存带宽瓶颈。在 3 GHz 时,相对于其内存带宽,它的计算量仍然很大。但比例不那么不平衡。
*假设 SPR 使用 DDR5-5200
其他 CPU 每个 FLOP 的带宽更高,但这主要是因为它们的吞吐量要低得多。GPU(和 A64FX)将其有利的带宽与计算比率归功于容量有限的紧密集成的内存子系统。与其他服务器芯片一样,Prodigy 可以配备数百 GB 的 DRAM。GPU 通常不能。
因此,Prodigy 很有可能成为具有竞争力的 HPC 或 AI 芯片,即使它实现不了它的时钟目标。除非出现重大缺陷,否则受吞吐量限制的 HPC 和 AI 应用程序可以从 Prodigy 的矢量单元中受益。Prodigy 最大的弱点,比如软件生态系统就显得不那么重要,因为研究人员和 AI 人员通常开发专门的系统。HPC 和 AI 代码也应该足够规则,以至于 Prodigy 较弱的分支预测器不会阻止它。
11
Server
服务器工作负载更复杂。与竞争服务器芯片相比,Prodigy 具有较弱的分支预测器和较低的缓存缓存容量。如果没有高时钟,Prodigy 的单核性能可能难以与之竞争。这不一定是一个大问题——ARM 进入服务器领域表明,即使每核性能没有竞争力,高核数芯片仍有空间(当然它必须足够好用才行)。
但ARM在服务器市场立足的背后还有其他因素。ARM 的内核以低功耗和高密度为目标。与英特尔和 AMD 不同,它们不会尝试涵盖广泛的功率和性能目标。这种专业化让 ARM 创建了适合云应用程序的更高核心数的芯片,同时保持在可接受的功率和成本目标范围内。该专业化通过牺牲矢量吞吐量和峰值性能,从而使用较小的矢量单元和密集设计那些没有那么高时钟速度的单元。Prodigy 具有比任何 x86 芯片更大的矢量单元和更高的时钟,因此它很有可能不会像 ARM 内核那样缩减到低功耗。
如果 Prodigy 没有达到如此高的时钟,我认为他们没有明确的方法来抢占服务器市场的一部分。他们不太可能在高密度市场上超越 ARM。如果没有巨大的时钟速度优势,它们不太可能在低线程工作负载中击败 x86 内核。并且当 Tachyum 致力于让 Prodigy 被流片出来时,没有人会坐以待毙。AMD 正在准备发布基于 Zen 4 的 Genoa 和 Bergamo。后者将拥有 128 个 Zen 4 核心,并减少缓存设置,与 Prodigy 的核心数量相匹配。Ampere Computing 正在开发 Altra 的继任者,它可能具有超过 128 个内核。Prodigy 当然会保留矢量吞吐量优势,但矢量吞吐量并不是服务器市场的决定性因素,就像 HPC 和 AI 一样。
12
结论
技术趋势通常是循环的。几十年前,服务器、客户端系统和超级计算机慢慢融合以使用类似的硬件。例如,在 2000 年代后期,AMD 的六核 K10 芯片在客户端系统中作为 Phenom X6 提供服务,在服务器和超级计算机中作为 Opteron 2435 提供服务。但在过去十年中,这种趋势一直在缓慢逆转。超级计算机通常使用 GPU 加速来提高吞吐量,而针对 HPC 的 GPU 架构和针对客户端平台的架构之间的差异越来越大。Ampere 和亚马逊已经为云计算优化了专门的服务器芯片。英特尔和 AMD 在所有三个类别中仍然使用相同的架构,但即使这样,它们也在定制芯片以适应不同的市场。例如,服务器形式的 Skylake 将额外的 L2 和矢量单元附加到核心上,并使用网状互连。AMD 计划以第二种形式发布 Zen 4,名为 Zen 4c,它以缓存容量换取核心数量,应该更适合云计算。
Tachyum 的 Prodigy 代表了逆势而上的勇敢尝试。它将 GPU 的矢量吞吐量与 CPU 的单线程性能相结合,但代价是高功耗。然而,我们仍然怀疑 Tachyum 如何在面临所有障碍的情况下实现这一切。我们确实向 Tachyum 询问了他们是如何实现 500mm2 的 CPU 的,虽然我们无法透露他们告诉我们的内容,但我们仍然对他们在 N5 上实现这一点持怀疑态度,因为他们不仅拥有大量矢量单元,还由于芯片上有大量的 DDR5 和 PCIe 5的 PHY,导致的大规模模拟电路的数量。
即使 Prodigy 按计划进入市场,它也将面临激烈的竞争老牌玩家及其专业产品。使用单一架构服务于不同的细分市场将使 Tachyum 能够利用其有限的工程资源扩大其业务范围。但是,除了专注于工程工作之外,该策略并没有太多优势。你不能仅仅因为两者都使用相同的芯片,就让服务器充当 HPC 节点的双重职责。超级计算集群具有极高速的网络和分布式存储,因此节点可以一起解决同一个问题。数据中心不会有同样的高速网络,因为响应互联网请求不需要几乎一样多的带宽。最后,Tachyum将面临一场艰苦的战斗,以建立围绕其ISA的软件生态系统,同时在途中遭受二进制翻译。对于一家小型初创公司来说,要处理很多事情,我们祝他们好运。
*免责:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。